LyScript 插件提供的反汇编系列函数虽然能够实现基本的反汇编功能,但在实际使用中,可能会遇到一些更为复杂的需求,此时就需要根据自身需要进行二次开发,以实现更加高级的功能。本章将继续深入探索反汇编功能,并将介绍如何实现反汇编代码的检索、获取上下一条代码等功能。这些功能对于分析和调试代码都非常有用,因此是书中重要的内容之一。在本章的学习过程中,读者不仅可以掌握反汇编的基础知识和技巧,还能够了解如何进行插件的开发和调试,这对于提高读者的技能和能力也非常有帮助。
4.10.1 搜索内存机器码特征 首先我们来实现第一种需求,通过LyScript插件实现搜索内存中的特定机器码,此功能当然可通过scan_memory_all()系列函数实现,但读者希望你能通过自己的理解调用原生API接口实现这个需求,要实现该功能第一步则是需要封装一个GetCode()函数,该函数的作用是读取进程数据到内存中。
其中dbg.get_local_base()用于获取当前进程内的首地址,而通过start_address + dbg.get_local_size()的方式则可获取到该程序的结束地址,当确定了读取范围后再通过dbg.read_memory_byte(index)循环即可将程序的内存数据读入,而ReadHexCode()仅仅只是一个格式化函数,这段程序的核心代码可以总结为如下样子;
def ReadHexCode (code ): hex_code = [] for index in code: if index >= 0 and index <= 15 : hex_code.append("0" + str (hex (index).replace("0x" ,"" ))) else : hex_code.append(hex (index).replace("0x" ,"" )) return hex_code def GetCode (): try : ref_code = [] dbg = MyDebug() connect_flag = dbg.connect() if connect_flag != 1 : return None start_address = dbg.get_local_base() end_address = start_address + dbg.get_local_size() for index in range (start_address,end_address): read_bytes = dbg.read_memory_byte(index) ref_code.append(read_bytes) dbg.close() return ref_code except Exception: return False
接着则需要读者封装实现一个SearchHexCode()搜索函数,如下这段代码实现了在给定的字节数组中搜索特定的十六进制特征码的功能。
具体而言,函数接受三个参数:Code表示要搜索的字节数组,SearchCode表示要匹配的特征码,ReadByte表示要搜索的字节数。
函数首先获取特征码的长度,并通过一个for循环遍历给定字节数组中的所有可能匹配的位置。对于每个位置,函数获取该位置及其后面SearchCount个字节的十六进制表示形式,并将其与给定的特征码进行比较。如果有一位不匹配,则计数器重置为0,否则计数器加1。如果计数器最终等于特征码长度,则说明已找到完全匹配的特征码,函数返回True。如果遍历完整个数组都没有找到匹配的特征码,则函数返回False。
def SearchHexCode (Code,SearchCode,ReadByte ): SearchCount = len (SearchCode) for item in range (0 ,ReadByte): count = 0 OpCode = Code[ 0 +item :SearchCount+item ] try : for x in range (0 ,SearchCount): if OpCode[x] == SearchCode[x]: count = count + 1 if count == SearchCount: return True exit(0 ) except Exception: pass return False
有了这两段程序的实现流程,那么完成特征码搜索功能将变得很容易实现,如下主函数中运行后则可搜索进程内search中所涉及到的机器码,当搜索到后则返回一个状态。
if __name__ == "__main__" : ref_code = GetCode() if ref_code != False : hex_code = ReadHexCode(ref_code) code_size = len (hex_code) search = ['c0' , '74' , '0d' , '66' , '3b' , 'c6' , '77' , '08' ] ret = SearchHexCode(hex_code, search, code_size) if ret == True : print ("特征码 {} 存在" .format (search)) else : print ("特征码 {} 不存在" .format (search)) else : print ("读入失败" )
由于此类搜索属于枚举类,所以搜索效率会明显变低,搜索结束后则会返回该特征值是否存在的一个标志;
4.10.2 搜索内存反汇编特征 而与之对应的,当读者搜索反汇编代码时则无需自行实现内存读入功能,LyScript插件内提供了dbg.get_disasm_code(eip,1000)函数,可以让我们很容易的实现读取内存的功能,如下案例中,搜索特定反汇编指令集,当找到后返回其内存地址;
from LyScript32 import MyDebugdef SearchOpCode (OpCodeList,SearchCode,ReadByte ): SearchCount = len (SearchCode) for item in range (0 ,ReadByte): count = 0 OpCode_Dic = OpCodeList[ 0 + item : SearchCount + item ] try : for x in range (0 ,SearchCount): if OpCode_Dic[x].get("opcode" ) == SearchCode[x]: count = count + 1 if count == SearchCount: return OpCode_Dic[0 ].get("addr" ) exit(0 ) except Exception: pass if __name__ == "__main__" : dbg = MyDebug() connect_flag = dbg.connect() print ("连接状态: {}" .format (connect_flag)) eip = dbg.get_register("eip" ) disasm_dict = dbg.get_disasm_code(eip,1000 ) SearchCode = [ ["ret" , "push ebp" , "mov ebp,esp" ], ["push ecx" , "push ebx" ] ] for item in range (0 ,len (SearchCode)): Search = SearchCode[item] ret = SearchOpCode(disasm_dict,Search,1000 ) if ret != None : print ("指令集: {} --> 首次出现地址: {}" .format (SearchCode[item],hex (ret))) dbg.close()
如上代码当搜寻到SearchCode内的指令序列时则自动输出内存地址,输出效果图如下所示;
4.10.3 获取上下一条汇编指令 LyScript 插件默认并没有提供上一条与下一条汇编指令的获取功能,笔者认为通过亲自动手封装实现功能能够让读者更好的理解内存断点的工作原理,则本次我们将亲自动手实现这两个功能。
在x64dbg中,软件断点的实现原理与通用的软件断点实现原理类似。具体来说,x64dbg会在程序的指令地址处插入一个中断指令,一般是int3指令。这个指令会触发一个软件中断,从而让程序停止执行,等待调试器处理。在插入中断指令之前,x64dbg会先将这个地址处的原始指令保存下来。这样,当程序被调试器停止时,调试器就可以将中断指令替换成原始指令,让程序恢复执行。
为了实现软件断点,x64dbg需要修改程序的可执行代码。具体来说,它会将指令的第一个字节替换成中断指令的操作码,这样当程序执行到这个指令时就会触发中断。如果指令长度不足一个字节,x64dbg会将这个指令转换成跳转指令,跳转到另一个地址,然后在这个地址处插入中断指令。
此外在调试器中设置软件断点时,x64dbg会根据指令地址的特性来判断是否可以设置断点。如果指令地址不可执行,x64dbg就无法在这个地址处设置断点。另外,由于软件断点会修改程序的可执行代码,因此在某些情况下,设置过多的软件断点可能会影响程序的性能。
读者注意:实现获取下一条汇编指令的获取,需要注意如果是被命中的指令,则此处应该是CC断点占用一个字节,如果不是则正常获取到当前指令即可。
1.我们需要检查当前内存断点是否被命中,如果没有命中则说明,此处需要获取到原始的汇编指令长度,然后与当前eip地址相加获得。
2.如果命中了断点,则此处又会两种情况,如果是用户下的断点,则此处调试器会在指令位置替换为CC断点,也就是汇编中的init停机指令,该指令占用1个字节,需要eip+1得到。而如果是系统断点,EIP所停留的位置,则我们需要正常获取当前指令地址,此处调试器没有改动汇编指令,仅仅只下了异常断点。
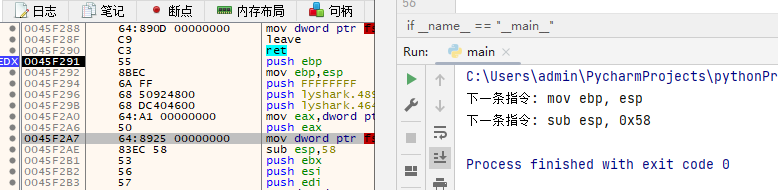
from LyScript32 import MyDebugdef get_disasm_next (dbg,eip ): next = 0 check_breakpoint = dbg.check_breakpoint(eip) if check_breakpoint == True : local_eip = dbg.get_register("eip" ) if local_eip == eip: dis_size = dbg.get_disasm_operand_size(eip) next = eip + dis_size next_asm = dbg.get_disasm_one_code(next ) return next_asm else : next = eip + 1 next_asm = dbg.get_disasm_one_code(next ) return next_asm return None elif check_breakpoint == False : dis_size = dbg.get_disasm_operand_size(eip) next = eip + dis_size next_asm = dbg.get_disasm_one_code(next ) return next_asm else : return None if __name__ == "__main__" : dbg = MyDebug() dbg.connect() eip = dbg.get_register("eip" ) next = get_disasm_next(dbg,eip) print ("下一条指令: {}" .format (next )) prev = get_disasm_next(dbg,4584103 ) print ("下一条指令: {}" .format (prev)) dbg.close()
如上代码则是显现设置断点的核心指令集,读者可自行测试是否可读取到当前指令的下一条指令,其输出效果如下图所示;
读者注意:获取上一条汇编指令时,由于上一条指令的获取难点就在于,我们无法确定当前指令的上一条指令到底有多长,所以只能用笨办法,逐行扫描对比汇编指令,如果找到则取出其上一条指令即可。
from LyScript32 import MyDebugdef get_disasm_prev (dbg,eip ): prev_dasm = None local_disasm = dbg.get_disasm_one_code(eip) eip = eip - 10 disasm = dbg.get_disasm_code(eip,10 ) for index in range (0 ,len (disasm)): if disasm[index].get("opcode" ) == local_disasm: prev_dasm = disasm[index-1 ].get("opcode" ) break return prev_dasm if __name__ == "__main__" : dbg = MyDebug() dbg.connect() eip = dbg.get_register("eip" ) next = get_disasm_prev(dbg,eip) print ("上一条指令: {}" .format (next )) dbg.close()
运行后即可读入当前EIP的上一条指令位置处的反汇编指令,输出效果如下图所示;