4.8 LyScript 学会扫描应用堆栈
堆栈是计算机中的两种重要数据结构 堆(Heap)和栈(Stack)它们在计算机程序中起着关键作用,在内存中堆区(用于动态内存分配)和栈区(用于存储函数调用、局部变量等临时数据),进程在运行时会使用堆栈进行参数传递,这些参数包括局部变量,临时空间以及函数切换时所需要的栈帧等。
- 栈(Stack)是一种遵循后进先出(LIFO)原则的线性数据结构。它主要用于存储和管理程序中的临时数据,如函数调用和局部变量。栈的主要操作包括压栈(添加元素)和弹栈(移除元素)。
- 堆(Heap)是一种树形数据结构,通常用于实现优先队列。堆中的每个节点都有一个键值(key),并满足特定性质。最常见的堆类型是二叉堆(包括最大堆和最小堆)。堆在计算机程序中的应用包括堆排序算法和内存管理等。
而针对栈地址的分析在漏洞挖掘中尤为重要,栈溢出(Stack Overflow)是一种计算机程序中的运行时错误,通常发生在缓冲区(buffer)中。缓冲区是一段内存空间,用于临时存储数据。当程序试图向栈中写入过多数据时,可能导致栈溢出,从而破坏其他内存区域或导致程序崩溃,严重的则可能会导致黑客控制EIP指针,而执行恶意代码。
栈溢出的原因主要有以下几点:
递归调用过深:当函数递归调用自身的层次过深时,可能导致栈溢出。这是因为每次函数调用都会在栈中分配内存,用于存储函数的局部变量和返回地址。如果递归层数太多,可能导致栈空间不足,从而引发栈溢出。
局部变量占用过多栈空间:如果函数中的局部变量(尤其是数组和结构体)占用过多栈空间,可能导致栈溢出。这种情况下,可以考虑将部分局部变量移到堆内存中,以减小栈空间的压力。
缓冲区溢出:当程序向缓冲区写入的数据超过其分配的空间时,可能发生缓冲区溢出。这种溢出可能导致栈空间中的其他数据被破坏,从而引发栈溢出。
LyScript 插件中提供了针对堆栈的操作函数,对于堆的开辟与释放通常可使用create_alloc()及delete_alloc()在之前的文章中我们已经使用了堆创建函数,本章我们将重点学习针对栈的操作函数,栈操作函数有三种,其中push_stack用于入栈,pop_stack用于出栈,而最有用的还属peek_stack函数,该函数可用于检查指定堆栈位置处的内存参数,利用这个特性就可以实现,对堆栈地址的检测,或对堆栈的扫描等。
读者注意:由于peek_stack命令传入的堆栈下标位置默认从0开始,而输出的结果则一个十进制有符号长整数,一般而言有符号数会出现复数的情形,读者在使用时应更具自己的需求自行转换。
而针对有符号与无符号数的转换也很容易实现,long_to_ulong函数用于将有符号整数转换为无符号整数(long_to_ulong)而与之对应的ulong_to_long函数,则用于将无符号整数转换为有符号整数(ulong_to_long)。这些函数都接受一个整数参数(inter)和一个布尔参数(is_64)。当 is_64 为 False 时,函数处理32位整数;当 is_64 为 True 时,函数处理64位整数。
有符号整数转无符号数(long_to_ulong):通过将输入整数与相应位数的最大值执行按位与操作
(&)来实现转换。对于32位整数,使用(1 << 32) - 1计算最大值;对于64位整数,使用(1 << 64) - 1计算最大值。无符号整数转有符号数(ulong_to_long):通过计算输入整数与相应位数的最高位的差值来实现转换。首先,它使用按位与操作
(&)来计算输入整数与最高位之间的关系。对于32位整数,使用(1 << 31) - 1 和 (1 << 31);对于64位整数,使用(1 << 63) - 1和(1 << 63)。然后,将这两个结果相减以获得有符号整数。
from LyScript32 import MyDebug |
如上代码中我们在当前堆栈中向下扫描10条,并通过转换函数以此输出该堆栈信息的有符号与无符号形式,这段代码输出效果如下图所示;

我们继续完善这个功能,通过使用get_disasm_one_code()获取到堆栈的反汇编代码,并以此来进行更多的判断形势,如下代码中只需要增加反汇编一行功能即可。
if __name__ == "__main__": |
运行上代码,将自动扫描前十行堆栈中的反汇编指令,并输出如下图所示的功能;
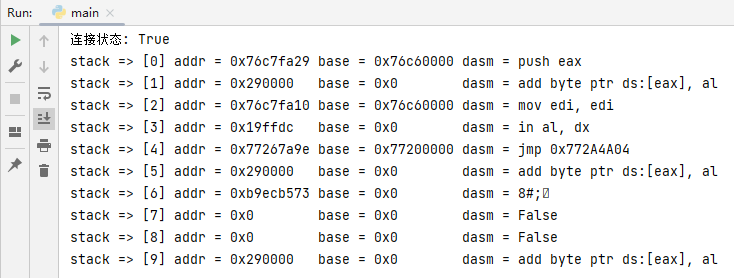
如上图我们可以得到堆栈处的反汇编参数,但如果我们需要检索堆栈特定区域内是否存在返回到模块的地址,该如何实现呢?
该功能的实现其实很简单,首先需要得到程序全局状态下的所有加载模块的基地址,然后得到当前堆栈内存地址内的实际地址,并通过实际内存地址得到模块基址,对比全局表即可拿到当前模块是返回到了哪个模块的。
if __name__ == "__main__": |
运行如上代码片段,则会输出如下图所示的堆栈返回位置;
