Masscan 是一款极为高效的端口扫描工具,以其卓越的扫描速度和大规模扫描能力而著称。该工具不仅支持 TCP 和 UDP 协议的扫描,还允许用户根据需求灵活指定多个目标和端口。Masscan 通过采用先进的网络性能优化技术,充分利用操作系统的资源和多核处理能力,实现了极高的扫描效率和吞吐量。其强大的性能使它能在短时间内扫便互联网的每个角落。使用 Masscan,用户可以迅速了解目标主机的服务状态和潜在漏洞,并且工具提供多种灵活的输出格式和报告,便于后续的分析和处理。
源代码编译 由于该扫描器的底层采用了 Npcap 接口实现,因此在使用扫描器之前,用户需要先下载 并安装Npcap库。安装完成后,用户需要下载Masscan的源代码,可以点击masscan-1.3.2.zip 下载版本。
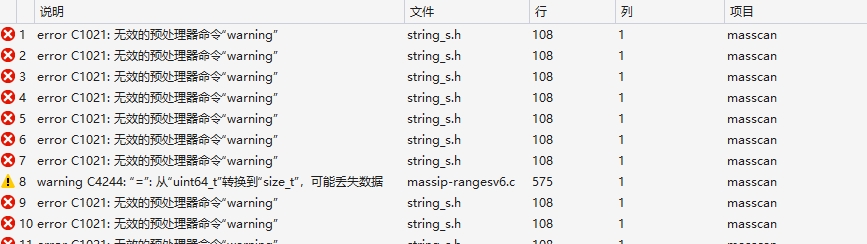
我们以下载源代码为例,下载好以后将其解压缩至任意位置。其中masscan-1.3.2/vs10目录下为Windows平台下的解决方案,读者可以使用Visual Studio打开该项目。在打开后会让读者升级项目此时点击升级即可,当升级结束后若直接对项目进行编译则会出现错误提示。
此时,读者可打开微软 针对编译器的说明网站,由于笔者使用的是Visual Studio 2013则其对应的_MSC_VER为1800,读者只需要记录下这个编号。
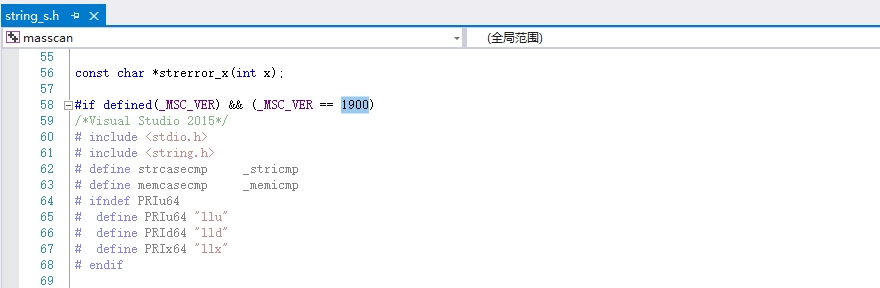
接着,读者可在解决方案管理器内找到misc目录,并打开string_s.h头文件,打开后定位到第58行并将其中的1900替换为1800并保存文件,至此再次点击编译生成即可。当生成结束后会在其bin目录下得到masscan.exe扫描器成品。
使用扫描器探测 使用Masscan扫描常见的TCP和UDP端口,可以在命令中直接指定。但默认情况下只会扫描TCP端口,若要扫描UDP端口则需要额外的参数配置。不过,Masscan 对于UDP扫描的支持并不如TCP扫描那样全面,建议在需要进行深入的UDP扫描时使用Nmap等工具。
我们通过使用-p参数来执行扫描常见的TCP端口,此处进扫描的端口包括 FTP(21)、SSH(22)、Telnet(23)、SMTP(25)、DNS(53)、HTTP(80)、POP3(110)、NetBIOS(139)、IMAP(143)、HTTPS(443)、SMB(445)、RDP(3389)。使用U来指定扫描UDP端口,此处扫描的端口包括DNS(53)、NTP(123)、SNMP(161),在扫描时我们通过使用0.0.0.0/8来指定网段。使用-oJ指定将扫描结果生成为JSON格式的报告,当然也可使用-oX指定生成XML报告。
masscan -p21,22,23,25,53,80,110,139,143,443,445,3389,U:53,U:123,U:161 0.0.0.0/8 -oJ output.json
若要扫描整个互联网则需要通过--exclude 255.255.255.255来指明。如下命令所示,通过0.0.0.0/0指定扫描全网段,并通过-p参数指定仅扫描HTTP(80)及HTTPS(443),执行命令后则会对整个互联网中的所有Web服务器进行探测,并输出为output_all.json格式的报告。
masscan -p80,443 0.0.0.0/0 --exclude 255.255.255.255 -oJ output_all.json
运用GeoIP2数据库解析 GeoIP2 是由MaxMind提供的一套地理位置数据库和API,用于将IP地址映射到地理位置信息。GeoIP2 数据库可以提供关于IP地址的详细地理信息,如国家、城市、经纬度、时区、自治系统(AS)等。其被广泛应用于各类需要地理位置数据的场景,如内容定制、安全、广告投放和数据分析等。
GeoIP2数据包含两部分内容,首先读者需要使用pip install geoip2来安装Python版本的接口,其次读者还需要自行下载对应的GeoLite2 database 数据库文件。
解析扫描结果 在之前我们通过使用Masscan扫描器扫描了世界范围内的所有Web服务器存活状态,并将扫描结果存储为了output_all.json格式的JSON文件中,接下来我们将通过使用Python解析这个数据库文件,并输出解析到的结果。
封装parse_scan_results函数,该函数接收一个扫描结果,并将该扫描结果解析为一个列表嵌套字典的格式,其中包含了基本的扫描信息,例如主机IP地址、扫描时间、端口号、TTL值等,并返回这个列表给调用者。
import jsonfrom datetime import datetime, timezoneimport geoip2.database""" 解析扫描结果文件,并返回一个包含字典的列表。 :param filename: 包含扫描结果的 JSON 文件路径 :return: 一个包含解析结果的列表,每个元素是一个字典 """ def parse_scan_results (filename ): results_list = [] with open (filename, 'r' ) as file: data = json.load(file) for result in data: ip = result['ip' ] timestamp = int (result['timestamp' ]) readable_time = datetime.fromtimestamp(timestamp, timezone.utc).strftime('%Y-%m-%d %H:%M:%S' ) for port_info in result['ports' ]: port = port_info['port' ] ttl = port_info['ttl' ] result_dict = { 'IP地址' : ip, '扫描时间' : readable_time, '端口' : port, 'TTL' : ttl } results_list.append(result_dict) return results_list
封装get_geo_info函数,该函数通过使用GeoIP2数据库,打开并查询IP地址的详细位置信息,并将该信息转换为一个字典格式返回给调用者。
""" 通过 GeoIP2 数据库查询 IP 地址的地理信息。 :param ip_address: 需要查询的 IP 地址 :param db_path: GeoIP2 数据库文件的路径 :return: 包含地理信息的字典 """ def get_geo_info (ip_address, db_path ): try : reader = geoip2.database.Reader(db_path) response = reader.city(ip_address) geo_info = { '国家' : response.country.name, '国家ISO代码' : response.country.iso_code, '省份' : response.subdivisions.most_specific.name, '省份ISO代码' : response.subdivisions.most_specific.iso_code, '城市' : response.city.name, '邮政编码' : response.postal.code, '纬度' : response.location.latitude, '经度' : response.location.longitude, '时区' : response.location.time_zone, '精度半径' : response.location.accuracy_radius, '大洲' : response.continent.name, '大洲代码' : response.continent.code } reader.close() return geo_info except FileNotFoundError: return {} except geoip2.errors.AddressNotFoundError: return {} except Exception as e: return {}
封装combine_scan_geo_info函数,用于将结合扫描结果和地理信息,生成包含完整信息的列表嵌套字典。封装format_combined_results函数,用于 格式化解析后的扫描结果和地理信息,并返回一个包含字典的列表。
""" 结合扫描结果和地理信息,生成包含完整信息的列表嵌套字典。 :param scan_results: 扫描结果列表 :param db_path: GeoIP2 数据库文件的路径 :return: 包含完整信息的列表,每个元素是一个字典 """ def combine_scan_geo_info (scan_results, db_path ): combined_results = [] for result in scan_results: ip = result['IP地址' ] geo_info = get_geo_info(ip, db_path) combined_result = {**result, **geo_info} combined_results.append(combined_result) return combined_results """ 格式化解析后的扫描结果和地理信息,返回一个包含字典的列表。 :param results_list: 包含扫描结果和地理信息的列表,每个元素是一个字典 :return: 格式化后的结果列表 """ def format_combined_results (results_list ): formatted_results = [] for result in results_list: formatted_result = { "IP地址" : result.get("IP地址" , "" ), "扫描时间" : result.get("扫描时间" , "" ), "端口" : result.get("端口" , "" ), "TTL" : result.get("TTL" , "" ), "国家" : result.get("国家" , "" ), "国家ISO代码" : result.get("国家ISO代码" , "" ), "省份" : result.get("省份" , "" ), "省份ISO代码" : result.get("省份ISO代码" , "" ), "城市" : result.get("城市" , "" ), "邮政编码" : result.get("邮政编码" , "" ), "纬度" : result.get("纬度" , "" ), "经度" : result.get("经度" , "" ), "时区" : result.get("时区" , "" ), "精度半径" : result.get("精度半径" , "" ), "大洲" : result.get("大洲" , "" ), "大洲代码" : result.get("大洲代码" , "" ) } formatted_results.append(formatted_result) return formatted_results
封装analyze_ip_distribution函数,该函数用于分析IP地址的地理分布情况,统计每个国家的IP地址数量,并返回详细信息。
""" 分析 IP 地址的地理分布情况,统计每个国家的 IP 地址数量,并返回详细信息。 :param results_list: 包含扫描结果和地理信息的列表,每个元素是一个字典 :return: 包含国家、IP 列表和 IP 数量的列表,每个元素是一个字典 """ def analyze_ip_distribution (results_list ): country_distribution = {} for result in results_list: country = result.get("国家" , "未知" ) ip_address = result.get("IP地址" , "" ) if country not in country_distribution: country_distribution[country] = {"国家" : country, "IP列表" : [], "数量" : 0 } country_distribution[country]["IP列表" ].append(ip_address) country_distribution[country]["数量" ] += 1 country_distribution_list = list (country_distribution.values()) return country_distribution_list
绘制全球IP数量分布 通过调用analyze_ip_distribution函数,我们还可以进一步分析这个扫描结果,获取到不同国家的IP地址信息,及所在国家的IP数量等,代码如下所示;
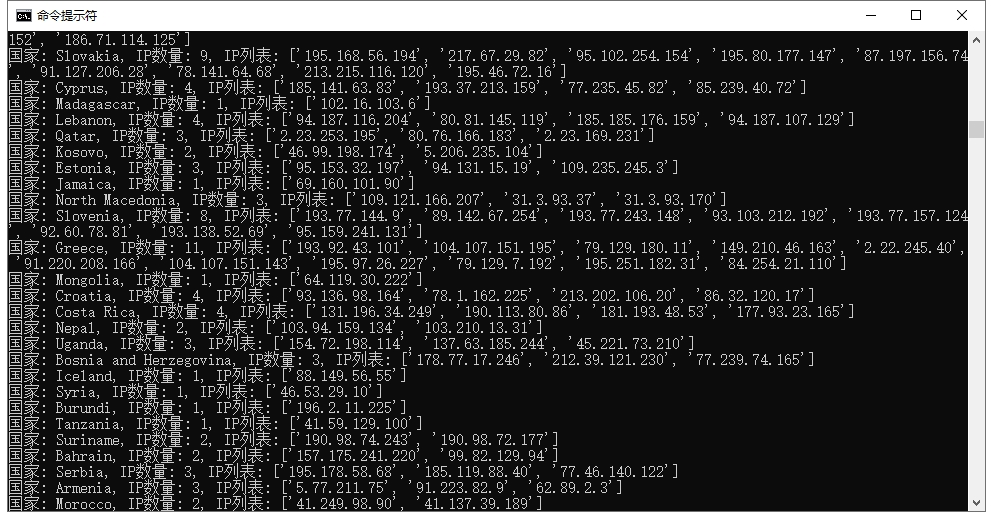
if __name__ == "__main__" : filename = './output_all.json' db_path = './GeoLite2-City.mmdb' scan_results = parse_scan_results(filename) combined_results = combine_scan_geo_info(scan_results, db_path) formatted_results = format_combined_results(combined_results) ip_distribution = analyze_ip_distribution(formatted_results) for country_info in ip_distribution: print (f"国家: {country_info['国家' ]} , IP数量: {country_info['数量' ]} , IP列表: {country_info['IP列表' ]} " )
运行上述代码,则可获取到不同国家的IP分布信息,如下图所示;因扫描仅进行了一小部分,则当前解析结果并不全面,仅用于研究代码案例。
接着通过使用pyecharts库,我们根据IP地址数量及国家分布,绘制一个数量分布柱状图,实现代码如下所示;
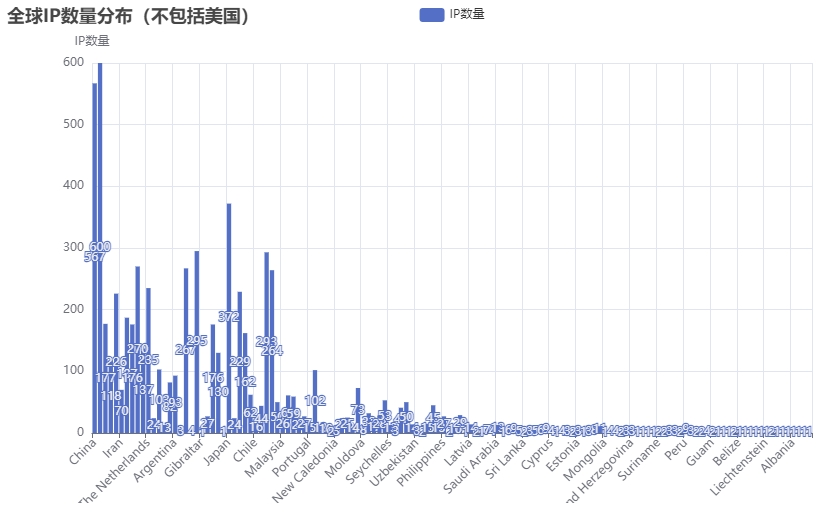
from pyecharts.charts import Barfrom pyecharts import options as optsif __name__ == "__main__" : filename = './output_all.json' db_path = './GeoLite2-City.mmdb' scan_results = parse_scan_results(filename) combined_results = combine_scan_geo_info(scan_results, db_path) formatted_results = format_combined_results(combined_results) ip_distribution = analyze_ip_distribution(formatted_results) filtered_ip_distribution = [country_info for country_info in ip_distribution if country_info["国家" ] != "United States" ] countries = [country_info["国家" ] for country_info in filtered_ip_distribution] ip_counts = [country_info["数量" ] for country_info in filtered_ip_distribution] bar = Bar() bar.add_xaxis(countries) bar.add_yaxis("IP数量" , ip_counts) bar.set_global_opts( title_opts=opts.TitleOpts(title="全球IP数量分布(不包括美国)" ), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45 )), yaxis_opts=opts.AxisOpts(name="IP数量" ) ) bar.render("ip_distribution.html" )
由于美国地区的IP地址过多,此处为了能展示柱状图效果则忽略美国地区的IP数量,这样能更好地展示柱状图分布,其运行效果如下图所示;
绘制全球IP位置分布 通过filename传入扫描后的记录信息,并调用GeoLite2-City.mmdb城市数据库文件,将IP地址解析并组合为一个新的扫描结果,通过循环输出给用户。
if __name__ == "__main__" : filename = './output_all.json' db_path = './GeoLite2-City.mmdb' scan_results = parse_scan_results(filename) combined_results = combine_scan_geo_info(scan_results, db_path) formatted_results = format_combined_results(combined_results) for result in formatted_results: print (result)
通过循环的方式依次验证IP地址所对应的数据库信息,读者可以获取到包括IP地址、扫描时间、扫描端口、TTL值、国家、国家ISO代码、省份、省份ISO代码、城市、邮政编码、纬度、经度、时区、精度半径、大洲、大洲代码等信息,如下图所示;
KML(Keyhole Markup Language)是一种用于表示地理数据的 XML 格式文件。KML 文件通常用于在地理信息系统(GIS)和地理应用(如 Google Earth 和 Google Maps)中显示地理数据。我们可以将扫描到的数据进行归纳,并调用generate_kml_from_results函数提取出所需要的IP地址及经纬度信息,并将其生成为一个独立的KML文件。
def retKML (addr, longitude, latitude ): try : longitude = float (longitude) except (TypeError, ValueError): longitude = 0.0 try : latitude = float (latitude) except (TypeError, ValueError): latitude = 0.0 kml = ( '<Placemark>\n' '<name>{}</name>\n' '<Point>\n' '<coordinates>{:.6f},{:.6f}</coordinates>\n' '</Point>\n' '</Placemark>\n' ).format (addr, longitude, latitude) return kml def generate_kml_from_results (results_list, output_file ): kmlheader = '<?xml version="1.0" encoding="UTF-8"?>\n<kml xmlns="http://www.opengis.net/kml/2.2">\n<Document>\n' kmlfooter = '</Document>\n</kml>\n' with open (output_file, "w" ) as f: f.write(kmlheader) for result in results_list: ip = result.get("IP地址" , "" ) longitude = result.get("经度" , 0.0 ) latitude = result.get("纬度" , 0.0 ) kml_placemark = retKML(ip, longitude, latitude) f.write(kml_placemark) f.write(kmlfooter) if __name__ == "__main__" : filename = './output_all.json' db_path = './GeoLite2-City.mmdb' scan_results = parse_scan_results(filename) combined_results = combine_scan_geo_info(scan_results, db_path) formatted_results = format_combined_results(combined_results) output_file = "GoogleEarth.kml" generate_kml_from_results(formatted_results, output_file)
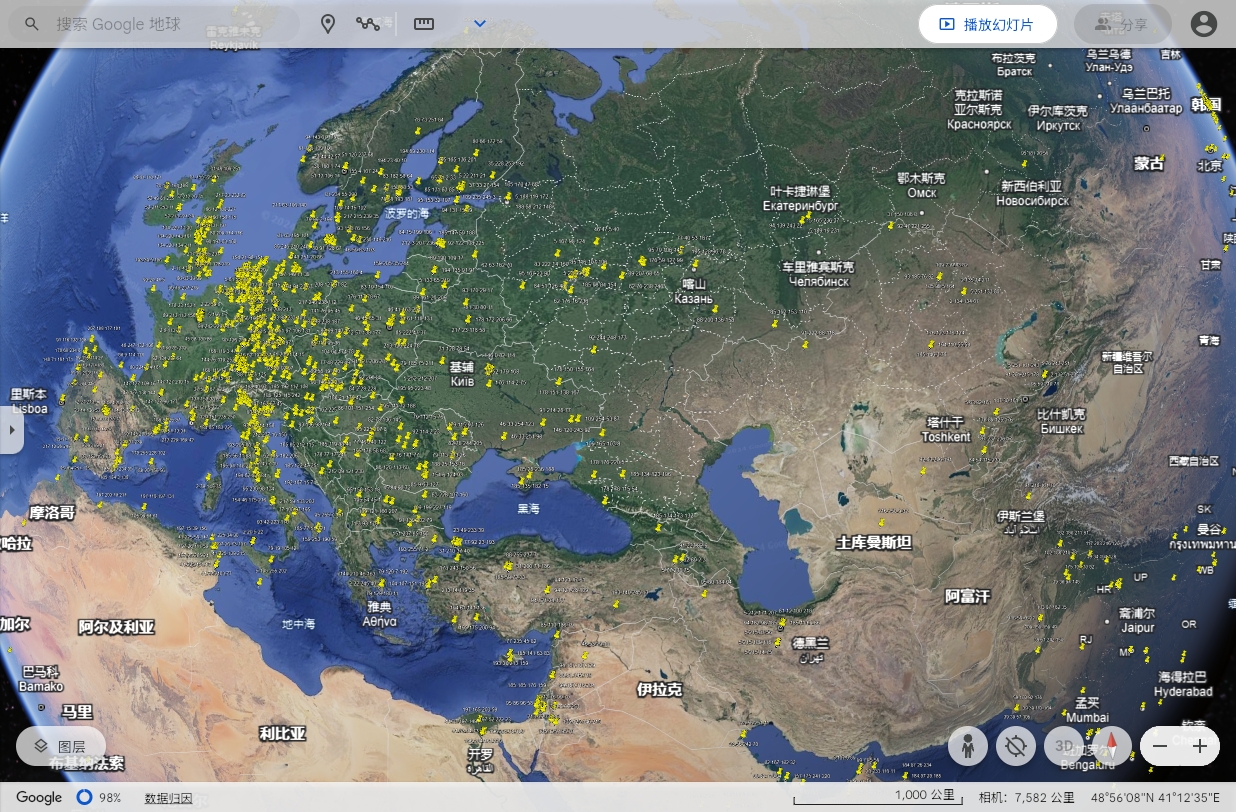
通过将KML文件导入到谷歌地图中,我们可以很直观的在地图上进行打点操作,打点后每个国家的详细信息都将被呈现,如下图所示;
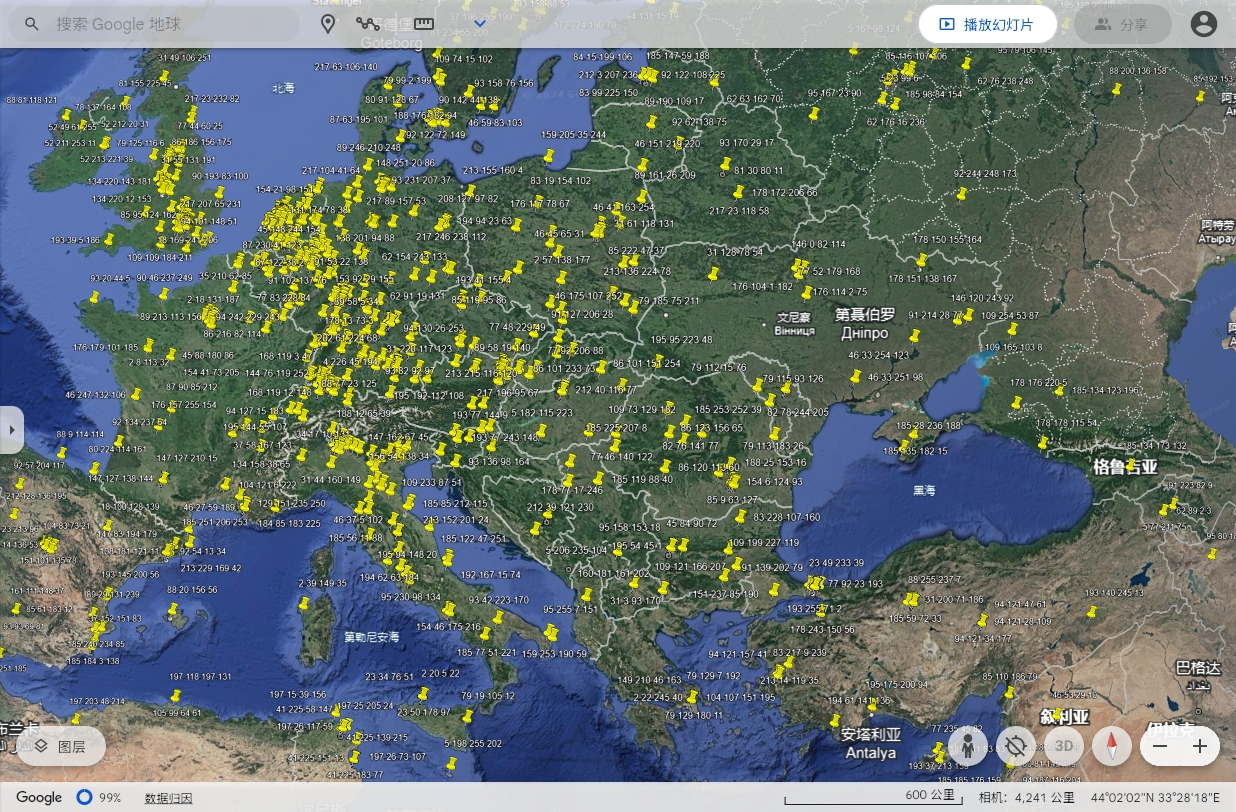
通过拉近一个国家,则可看到每一个打过标记的IP分布位置图,如下所示;
至此,本次的技术分享就到此结束了。事实上,在获取到IP地址的在线状态后,我们可以继续使用Nmap扫描器对其进行操作系统的鉴别。当鉴别到每一个IP地址的操作系统版本后,我们就可以推测出这个国家所使用的操作系统比例,并以此来衡量每个国家的操作系统普及程度及进一步评估其国家的系统安全系数。